
Microsoft shares tool that can mimic voice and speech with 3 seconds of sample audio
The software giant has shared a tool that can replicate voice and speech with just a few seconds of an audio sample.
The new technology is being referred to as "text to speech synthesis".
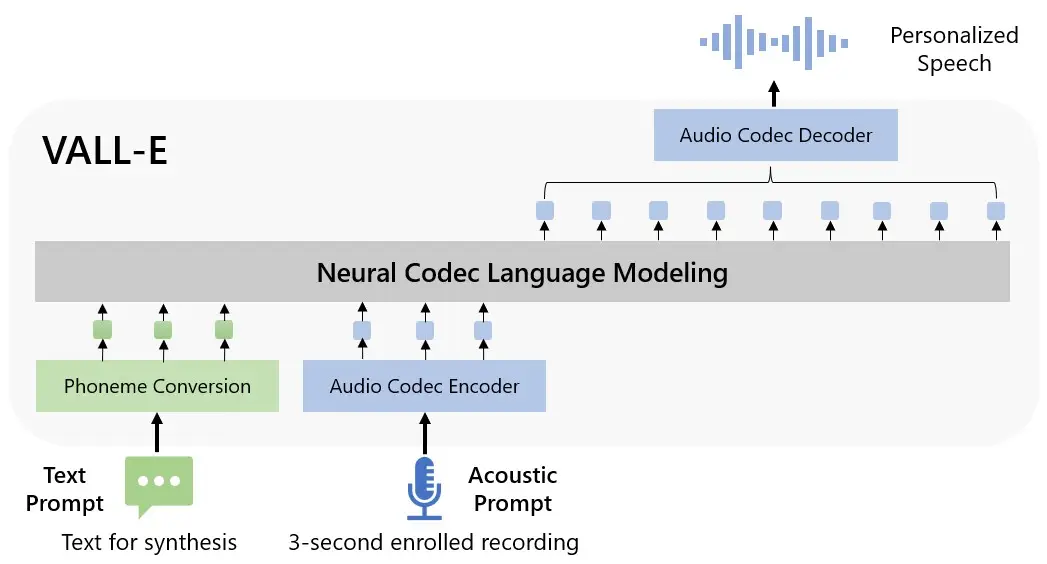
Microsoft explain that they have trained a neural codec language model, called VALL-E, to synthesise speech.
Advert
In a post on GitHub, Microsoft revealed that the text to speech synthesis training data stretched to "60K hours of English speech which is hundreds of times larger than existing systems."
Just using three seconds of an audio sample, VALL-E is able to accurately mimic voice and speech.
"VALL-E emerges in-context learning capabilities and can be used to synthesise high-quality personalised speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt," Microsoft outlines.
Not only is this new technology able to synthesise speech, but it can also take into consideration different emotions and moods that can influence the tone or pitch of speech.
The post details: "In addition, we find VALL-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis."
Such emotions and feelings include anger, sleepy, neutral, amused and disgusted with very distinctive variations differing between each one.
In short, the technology, created by Meta, analyses the ways in which a person sounds and then breaks down that specific information into various components.
Such components are called tokens and these are used as training data to establish matches between what the technology "understands" about how one particular voice would sound if it were to speak in words or phrases other than what was provided in three-second audio sample.
Or, as Microsoft puts it: "To synthesise personalised speech (e.g., zero-shot TTS), VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording and the phoneme prompt, which constrain the speaker and content information respectively.

"Finally, the generated acoustic tokens are used to synthesise the final waveform with the corresponding neural codec decoder."
While the technology is revolutionary in many ways, the software corporation has acknowledged the "potential risks" that surround VALL-E in an ethics statement also posted on GitHub.
It reads: "Since VALL-E could synthesise speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker.
"We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis.
"When the model is generalised to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesised speech detection model," it concludes.
Topics: Technology, Microsoft